Biography
Hi! This is Yiling Qiao. I earned my PhD in Computer Science from the University of Maryland, College Park, where I was advised by Prof. Ming Lin. I was previously a member of UMD GAMMA Group. During my undergraduate years, I was advised by Prof. Lin Gao and Prof. Xilin Chen.
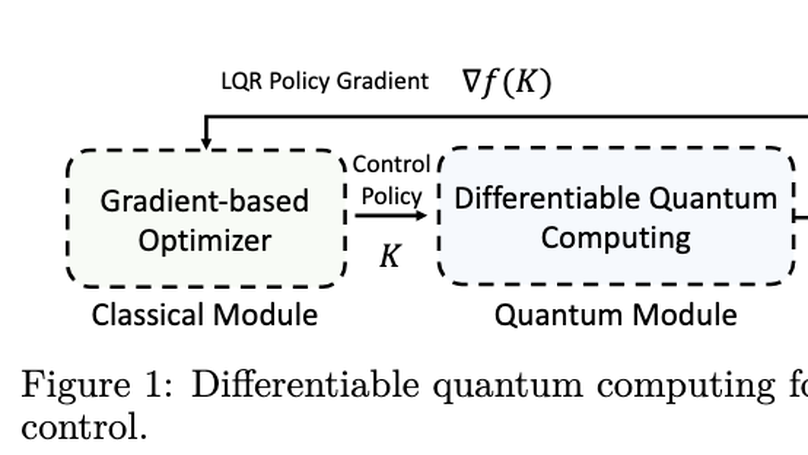
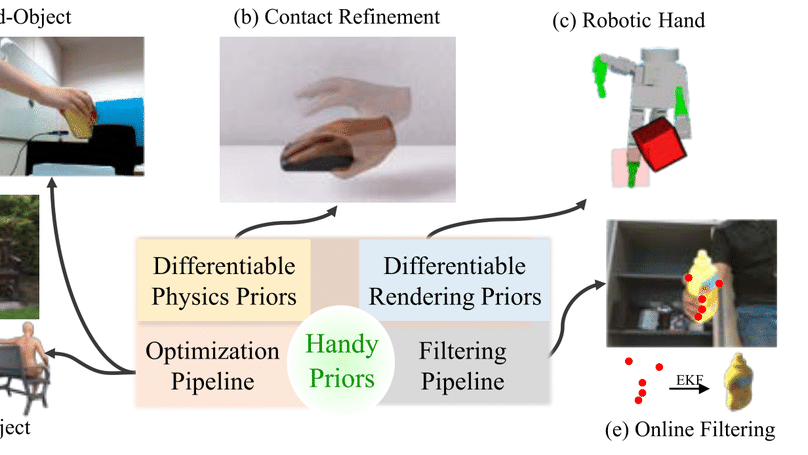
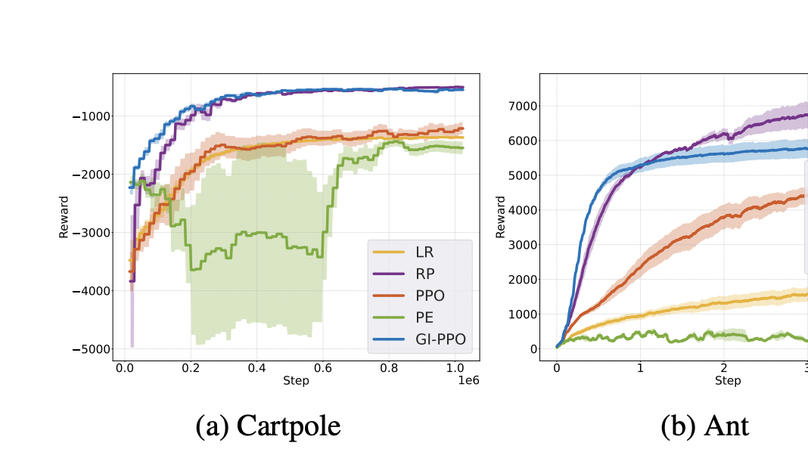
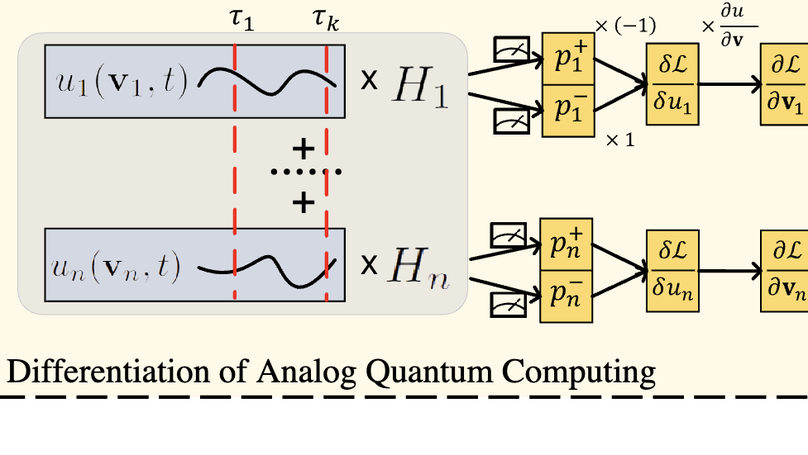
My research focuses on physically-based simulation, computer graphics, and machine learning, and has been supported by the Meta PhD Fellowship (AR/VR Computer Graphics Track). I am honored to have been awarded Larry S. Davis Dissertation Award. Recently, we introduced Genesis, a generative world designed for general-purpose robotics and embodied AI. Below is my Research Statement.
Software:
- Differentiable simulation:
- Simulation + NeRF:
Ph.D. Student in Computer Science, 2019 - present
University of Maryland, College Park
B.E. in Computer Science, 2015 - 2019
University of Chinese Academy of Sciences
B.S. in Mathematics and Applied Mathematics, 2015 - 2019
University of Chinese Academy of Sciences